Wrap-up
Congratulations to the 118 teams who successfully calibrated the Timespace Machine and made it back home safely! Special congratulations to brain empty no thoughts for being the first team to do so, completing the hunt in just over 16 and a half hours. The race for the finish was tight, with both the second-placed Puzzles and Friendship and third-placed ⛭ MISCELLANEOUS SYMBOL HISUIAN QWILFISH finishing within an hour of the winning time!
We'd also like to shout out the following teams:
- puzzles too hard :c for getting the first solve in the hunt, on Motion Capture
- plugh for getting the first solve on The Foggy Plains
- brain empty no thoughts for getting the first solve on The Haunted Graveyard
- Mountain is High Enough for getting the first solve on The Abandoned Factory
- Puzzles and Friendship for getting the first solve on The Frozen Tundra
Kudos to a few teams for tackling some of our harder puzzles with gusto, getting the first forwardsolve on these puzzles:
- Team MATE Wants To Battle! for getting the first forwardsolve on LITS
- Unexpected Guild Members in Hisuian Area for getting the first forwardsolve on Trading Places
- Novel Hub for getting the first forwardsolve on Rig Your Own Tournament
- ⛭ MISCELLANEOUS SYMBOL HISUIAN QWILFISH for getting the first forwardsolve on Ouroboros
And finally, we'd like to recognize a few teams for their high-precision runs of the hunt:
- come back to us later for finishing the hunt with 0 incorrect guesses
- llamas for finishing the hunt, without taking any hints, with only 1 incorrect guess, which was a correct cluephrase on Rig Your Own Tournament
Please note that the rest of this wrap-up will contain spoilers for the hunt (the metameta answer is just a few lines below this warning). Turn back now if you don't want to be spoiled!
Story
Upon starting the hunt, teams found themselves stranded somewhere in timespace, with the Timespace Machine they had used to arrive having lost its bearings, and with it their way home. The only solution, it seemed, was for teams to navigate the region, collect samples from four significant points from which to calculate their coordinates, and hopefully find the way home.
Naturally, the environment was somewhat puzzling, requiring teams to solve puzzles as they traversed the region to find important points to sample. Eventually, after exploring the Foggy Plains, the Haunted Graveyard, the Abandoned Factory, and the Frozen Tundra, solvers were able to get their timespace bearings and FIND A SILPH ALIGNING with which to return home.
Writing the hunt
Probably the best place from which to start this wrapup is at the beginning, chronologically. The hunt was, believe it or not, actually planned for a release in either late 2022 or early-mid 2023. As you may or may not have noticed, we ended up going slightly over schedule. Here's a brief timeline:
- January 2022: First announcement re "Silph 2022". Writing team refreshes.
- February 2022: Structure concept doc written
- March 2022: Meta pun ideation / Meta writing begins!
- September 2022: Graveyard / Factory / Tundra metas finalized, feeders released
- November 2022: Plains feeders released
- April 2023: Structural gimmick cut
- 2023-2025: ???
- July 22, 2025: Metameta written
- July 25, 2025: Hunt starts!
Within the 2023-2025 period, the hunt "died" and was revived several times, gradually inching closer to completion each time. Eventually, after Mystery Hunt this year, we decided that we were close enough to completion that we could book dates on the calendar and wrap up the hunt. We hope this inspires everyone out there with a half-complete puzzle project to pick it back up!
Hunt structure
After our first properly large and public hunt in 2021, we had two main ideas about directions to take our next attempt in, mostly revolving around hunt structure.
Our first goal was to incorporate the first round more closely into the rest of the hunt, hopefully in a way that treated it structurally equivalently to the other rounds. At the time, most hunts adopted the conventional structure of having an "introductory" round, and then the "main" rounds in the rest of the hunt. We felt (and some feedback indicated) that although this provided accessible content for newer solvers, it also made the introductory round feel isolated from the rest of the hunt. Overall, we're quite happy with how our implementation of this panned out—a byproduct of this is that we didn't have an intro-round "meta wall", as a few teams noted positively in feedback.
The other main thing we wanted to do with our hunt was to introduce some kind of structural gimmick to it—after four years of traditional round structures, we were interested in exploring some mechanics that would add more dynamism to the hunt experience.
The original concept was that puzzles in the four rounds would be gimmicked in different ways:
- In the Foggy Plains, puzzles would have portions concealed by fog.
- In the Haunted Graveyard, puzzles would be "tampered with" by mischievous poltergeists. The exact implementation varied from puzzle to puzzle: in Jigsaudio, we suggested adding obfuscation to the audio clips in the form of spooky moans, while in Dimmer Wits, the ghosts had taken every single instance of a number out of the posts and dropped them all into a box at the top of the page.
- In the Abandoned Factory, the "parts" involved in each puzzle would all be mixed up together on the factory floor: specifically, the clues from each puzzle would be merged into one long list (one suggested implementation even had them all back-to-back in one long string with capitalization removed).
- In the Frozen Tundra, the interactive portions of each puzzle would be "frozen". For most puzzles, this imposed a rate limit on how many inputs solvers could attempt per unit time. In Homebrewed, we suggested that in the frozen state, the Cauldron would only ever produce Potions of Freezing. In fact, Cosmic Squad's panel-freezing mechanism is an artifact of this gimmick!
Of course, solvers wouldn't be forced to solve every puzzle in a gimmicked state; teams would get a device capable of undoing these changes, along with a battery pack that charged up enough to un-gimmick a puzzle every so often. Similar to how HMs (Hidden Machines) in the Pokémon games unblock natural obstacles in the game world, we proposed having solvers unlock HRs (Hunt Records) throughout the hunt to gradually increase the ungimmicking power solvers had. (This was, of course, named for the joke: "We're unveiling Silph Co.'s brand new HR Department! …what do you mean we were supposed to have one before?")
As you may have noticed, the hunt as it happened contained four completely ungimmicked (but moderately "themed") rounds. After some writing and testing, we started feeling like the gimmicks weren't adding much to the puzzles. This was due in part to some sentiment that the gimmicks were going to be there just for the sake of being there, without really adding much value. Additionally and perhaps more importantly, however, our limited testsolving resources made it hard to get testsolves with and without the HR modifications on different versions of our puzzles (our writing server contains just 13 users, with differing levels of activity). This was especially true of the Factory, which effectively forced all the puzzles to be ready before they could be properly tested, thereby entangling the testsolve states of five different puzzles. Ultimately, we dropped the concept; despite ending up without gimmicked rounds like we originally intended, we think we made the right decision for our manpower situation.
Themed rounds
One effect of the gimmick's temporary existence is that our rounds ended up slightly themed: the Tundra had several interactives in line with its rate-limiting gimmick, and the Factory had a few crosswords intended for the clue-mixing mechanic. Rather than try to skew away from this to even out the rounds, we thought it would be interesting to give these rounds a more pronounced "flavor", not unlike how different biomes in open-world exploration games come with unique sets of hazards and challenges. We thought this would also help make the back half of the hunt feel more like three distinct rounds than a homogenous series of 20ish puzzles. (Fun fact: this isn't even the first time we've done this! Oldheads will remember the Beauty round from Smogon Puzzle Hunt 2019, which contained only crosswords.)
Theming rounds does, of course, bring its own form of homogeneity to the hunt. Within each of the themed rounds, we explored how we could involve the concept of the round in different ways to establish a unique identity for each of the puzzles in that round while having them still feel like they revolved around the same core concept. When planning the spread of puzzles for Factory, for example, we tried to run the gamut of how "crosswordy" each puzzle was (crossword grid, variety crossword grid, clues with extraction grid, cryptic clues, and just clues). Over in the Tundra, although it's arguable that many of the blackbox puzzles were fundamentally similar at some level, we aimed to make the solving processes feel sufficiently different so that they didn't impinge on each others' solving spaces.
It was interesting to see the differing feedback regarding this decision. At least one mentioned in feedback forms that the Factory round ended up playing extremely difficult for them, to the point that they completed the Tundra meta before getting a single Factory solve; another referred to Factory as "a good mid-hunt morale booster" due to its short length. We were pleasantly surprised by the extent to which these theme-concentrated rounds magnified team strengths and weaknesses, since it's no longer possible for a team to completely solve around puzzle types they don't particularly vibe with.
On the whole, we're glad that our rounds made an impression on solvers despite not having additional round-wide gimmicks. Despite its difficulty and placement in the hunt, it seemed that many teams especially relished rising to the challenge posed by Tundra, and some word-solver-heavy teams seemed to enjoy feeling in their element throughout the Factory round. Finally, one solver suggested that the Graveyard was also a themed round, but themed around cursed puzzles. Given that it contained all of Plaintext Adventure, Dimmer Wits, LITS, and No Word Wordsearch, we're inclined to agree.
Pacing and unlocks
As with previous years, we gave a good deal of thought to how unlocking should work. The first detail we landed on was that the first round's meta shouldn't block the rest of the hunts, since doing so felt like it was implicitly setting up the intro round vs main round separation that we were trying to avoid. Quite a number of teams mentioned being grateful for this design choice, but we think it was probably especially useful for team Mountain is High Enough, who solved a whopping 17 feeder puzzles before cracking the Foggy Plains meta!
Since we figured our overall hunt structure was probably similar to that of ECPH (in the sense of comprising several structurally equivalent rounds), we spoke with them about their unlock structure to see if we could pick up any ideas from them. The structure turned out to be surprisingly simple: getting solve number X in round Y unlocks a fixed set of puzzles, mostly in that round but sometimes opening a new round.
- We had a few ideas for puzzle ordering we wanted our eventual unlock system and ordering to respect:
- Early on, we decided that the main sequence of round unlocks would be Plains > Graveyard > Factory > Tundra, with Factory overlapping heavily with the adjacent rounds to dissipate the concentration of word puzzles over a larger proportion of the hunt.
- To go with our earlier idea of reducing the separation of the first round from the rest of the hunt, we knew we wanted to unlock Graveyard strictly before the Plains meta unlocked.
- As much as possible, we wanted to avoid unlocking anything at the same time as a metapuzzle, since metapuzzle unlocks tend to draw attention and we didn't want to distract from a feeder unlocking simultaneously.
- Rather than have all the hardest puzzles appear in a single contiguous chunk somewhere in the hunt, we wanted to spread them out into two peaks, around one-third and two-thirds of the way into the hunt, and surround them with easier puzzles—we felt this would help to reduce the extent to which they would block teams' solving momentum and compete against each other for solver attention. These blocks ended up being LITS + Trading Places + Cross-Pollinator (unlocking after 1, 2, and 2 Graveyard solves respectively) and Rig Your Own Tournament + Ouroboros (3 Graveyard solves or 10 total solves and 2 Factory solves or 10 total solves respectively), with their "impact" on solve momentum being cushioned by easier puzzles nearby like Only Compact (Graveyard) and Fast-Fix Typist (Factory).
- Keeping in mind that more casual teams were likely to lose people as the hunt went on (and even hardcore, podium-chasing teams in the US were likely to have people go to sleep before they finished the hunt), we tried to unlock harder and grindier puzzles early where possible to allow teams to distribute the associated work while they still had more people.
- The exact positioning of some ubiquitous but specialized puzzle types, like grid logic or cryptic crossword clues, doesn't matter as much, since they tend to be polarizing: solvers who are proficient at those puzzle types are likely to hop into them regardless of where they appear, and solvers who aren't are unlikely to be persuaded to give them much more attention regardless of their placement.
- Ideally, we'd like to either force every team to solve at least one of Ouroboros or Rig Your Own Tournament (which we believed were the two hardest puzzles in the hunt) or at least make it inconvenient or inefficient to try to skip both, to strongly encourage teams to take one of these two puzzles on.
In the end, we implemented the ECPH system exactly in our hunt, with some added "emergency releases" caused by global unlock count to ensure that puzzle width didn't drop too low. These were additional unlock conditions added to the third puzzle in each non-Plains round to ensure that the number of "active feeders" a team had—unsolved feeders corresponding to a round where the meta hadn't been unlocked yet—never fell below 3:
- Dimmer Wits unlocked after one Graveyard solve or 5 global solves
- Fast-Fix Typist unlocked after one Factory solve or 10 global solves
- Homebrewed unlocked after one Tundra solve or 13 global solves
We attempted to implement the Ouroboros / Rig Your Own Tournament "encouragement" by unlocking them both early and only unlocking another puzzle in the round via an "emergency release" if there were no active non-Tundra puzzles remaining. Unfortunately, we somewhat underestimated the impact of backsolving on the global unlocks, resulting in quite a few teams (including, awkwardly, the winning team) getting around Ouroboros and Rig Your Own Tournament more easily than intended and unlocking the rest of the Tundra. We did adjust the Homebrewed global unlock from 13 to 14 a few hours into the hunt when we realized Homebrewed would unlock much earlier than intended, but ultimately the better solution would've been to not count solves after unlocking a meta towards this global unlock condition, thereby negating the impact of backsolves.
One outcome of this unlock structure is that teams ended up with quite a high unlock width fairly early on, since we had many multiple unlocks and even a few triple-unlocks early in the hunt: both of Graveyard and Factory unlocked with two puzzles in their round, alongside one puzzle in the unlocking round, increasing puzzle width by 2 at a time. We did consider the possibility that this might end up a little wide for teams, but at the same time we liked how it kind of replicated the wide-open—and, indeed, sometimes slightly overwhelming—experience of open-world exploration.
Difficulty
We've come a long way since we wrote our first puzzles for the Smogon Puzzle Hunts in 2018-2020, and even since the last installation of Silph it's been three and a half a years, and it seems that in the intervening years several members of our writing team have developed a taste for difficult puzzles. For this edition of Silph, we aimed to deliver a more compact set of puzzles with a generally higher difficulty than in Silph 2021, moving closer to (albeit not quite reaching) the per-puzzle difficulty levels of hunts like (pre-2023) Teammate or Galactic.
Overall, our audience seemed to respond favorably to the scope of this hunt in terms of length and difficulty. From the questions in our feedback form about length and difficulty, on a five-point scale: In terms of length, the hunt was rated an average of 3.42 (1 = much shorter than preferred / 5 = much longer than preferred). In terms of difficulty, the hunt was rated an average of 3.53 (1 = much easier than preferred / 5 = much harder than preferred).
Based on additional feedback, we think the slightly-above-ideal ratings were probably due in part to a lack of clear communication on the site pre-hunt about how hard we expected the hunt to be, and that given appropriate expectation-setting, the difficulty window we hit was broadly a sweet spot for most teams. We're sorry to all solvers who ended up with a much harder experience than they signed up for!
Zooming in closer to per-round difficulty, our hunt more closely resembles a "standard" intro-main structure, with the Plains being friendlier to newer solvers to act as a bit of a foothold. Ironically, this probably worked against our intention to reduce the separation between the first round and the rest of the hunt, since this necessarily led to a noticeable difficulty spike at the start of Graveyard. While arguably there were easier puzzles (like Only Compact) which we could have placed earlier in the round to try to ease solvers into the round, teams ultimately would have needed to solve the same set of puzzles in the hunt, and we felt it would be more inspiring to teams to open with some of the more conceptually or visually interesting puzzles in the round. In an ideal world, Graveyard probably could have been an "intermediate" round, but with puzzle difficulty as nebulous a concept as it is, and as a relatively mid-sized hunt, it's difficult to perfectly span the puzzle difficulty spectrum. We hope that teams that managed to push through the initial challenge found the rest of the hunt a much more even experience!
Future plans
As hard as it may be to believe, we didn't just decide after a couple of years off to start Silph up again; this hunt's writing did, in fact, take place over the last three and a half years, very slowly. As is evident from this intra-Silph gap, our collective writing team is somewhat lower on hunt-writing time and energy than we used to be; several of our key writers are reaching or have reached a stage in life where it's no longer feasible to spend several hundred hours every year writing puzzles. (As a fun fact, one of our team members started university just before the last Silph, and has since graduated, which we find hilarious.)
All of that is to say that it's unlikely that Silph will return with any regularity. While we don't want to close the door on another edition entirely, we expect that another one won't occur for at least another couple of years, if another one does happen at all. Whether this Silph was your first time solving with us or whether you've been around since 2018, we hope that you've enjoyed our puzzles and that we've brought you some interesting ideas, some smiles, and some good times.
Fun stuff
Stories we received
Cry-ptic
Torontotodiles: Being in a room of 6 people all shouting "Zut Zutt!" at each other was reward enough for doing the hunt as it is.
LITS
spinda^32 has the entire LITS alphabet memorized:

Trading Places
Hee-ho whipped out their card collection for this puzzle, complete with Japanese Rayquaza VMAX and custom proxies for some cards not on hand:

Cross-Pollinator v2.4
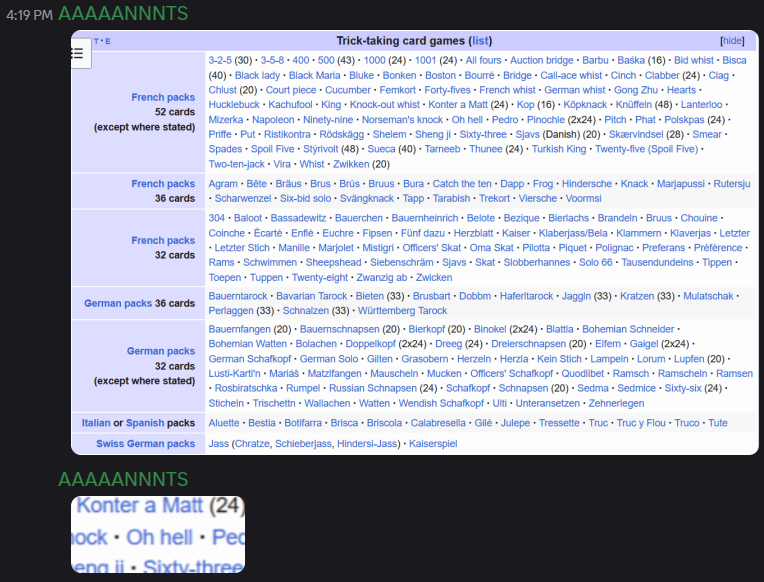
Alolan Carpet Installation trying to narrow down the possibilities on the "trick-taking game":
Fast-Fix Typist v2.7
RSVPuzzle: We went a little insane doing Fast Fix Typist because we had somehow gotten "STOP" instead of "SEAL", so we extracted a P and got CAPLIN SNAKE CHARMER and went crazy trying to figure out what a caplin snake charmer was. 4 of us spent a good hour Googling and coming up with crackpot theories about how we needed to reuse the gimmick and add a missing letter to make CHAPLIN SNAKE CHARMER, and this was actually about a snake charmer in a charlie chaplin movie. And after sleeping on it, we finally asked for a hint and I've truly never felt dumber LOL
Homebrewed
Dan City: We knew L51 worked on the hunt so when we got Homebrewed the first thing I did was Google "RUNESCAPE POTION CRAFTING." Then every time somebody new showed up to help (n=4) the first question that they asked was "did you google Runescape potion crafting?"
P Squad:
[2:54 PM] pluvi: omg
[2:55 PM] pluvi: the first letters spell out CRAMOMATIC P
[2:55 PM] pluvi: cram o matic is in pokemon sleep
[2:55 PM] Amaranth: cramomatic is not a sleep exclusive
[2:55 PM] Amaranth: its a swsh thing
[2:55 PM] Amaranth: and then they also added it to sleep
[2:58 PM] pluvi: this reminds me of when i heard the beatles song Come Together and i was like "woah ive heard this. from the suicide squad trailer" and got clowned on incredibly hard for knowing it from that
Alolan Carpet Installation: Our solving channel was named #cram-o-matic after our team name in the first hunt we did in that server, but we renamed it to #alolan-carpet-installation for this hunt. As soon as we got the first step in this puzzle we realized we had made a mistake and immediately changed it back.
Also:

The Frozen Tundra
Dan City: While we were working on the Frozen Tundra and mistakenly assumed the spirits always led travelers west, some of my team members were worried about always getting back to 1. Me, a mathematician, reassured them: "I think we're okay. In fact this setup reminds me of this famous conjecture..." But because I was so tunnel visioned on always going west I put two and two together and got 3. We hinted the puzzle. I was kind of embarrassed.
Answers we enjoyed
Motion Capture
GOOGLEENPASSANT- :praytrick:コンヘイトー- International Mushroom captive Organization
Sudoku Starter Pack
WOWTHANKSFIREFIGHTINGFORMAKINGTHELOGICINTHEBOTTOMMIDDLEBLOCKREALLYOBNOXIOUS- Team MATE Wants to Battle!BITCHWHAT- Crystal Maiden
Broken Mirrors
INMATHHELOVEDHISREFLECTION- many teams
Off By One
THEERRATUMSHOULDSAYCLUETWELVEORCLUEFOURTEEN- Eyjafjallajökull's CalderaLIGHTCORNFLOWERBLUETWO- Dan City
Tatami Mat
MINNESOTAMENTIONED- :praytrick:CHARACTER- Team MATE Wants to Battle!
Trading Places
PORKTOWER- honkerino poggerino (GPH 2023 mentioned!)
Answering Machine v9
ISTHISSOMEKINDOFTWISTEDJOKE- Dan City
The Abandoned Factory
SEDUCEEXMACHINA- usedCow, Team Eagle Time, Pokemon Petting Puzzlers (...Team Eagle Time also somehow submitted this to The Haunted Graveyard.)SCREENNEWIPHONE- Mystik Herrings🌀🎏
Rig Your Own Tournament
CHAMPIONNARCOTIC- Typhlosion's Stupid, Beedrill Isn'tUNFORTUNATEDOESNTBEGINTODESCRIBEMYTOURNAMENTTHESEJUDGESREWARDBLINDLUCKANDNOTHINGELSEIAMBEYO- Dan City
Ouroboros
REPTILIANROMANCE- Puzzles and Friendship
Cosmic Squad
TIFIEDLAUNCH- Unexpected Guild Members in Hisuian Area
The Frozen Tundra
TANGELARVESTALONFLAMELOETTANGELARVESTALONFLAMELOETTA- Dan City (elite ball knowledge required)
The Timespace Machine
FINDASILPHALBANIAN- ghostbloods
Statistics
As always, we collected some statistics on teams' progress through the hunt. You can check some of them out here:
- The Big Board we used to monitor teams' global progress
- A general stats page with information on puzzle solves, hints used, and backsolves
- A chart of solves over time for the first 30 teams to finish the hunt
Speed
Perhaps due to the wider unlock diameter in general this year, we got a really diverse spread of fastest-solving teams on each puzzle, with 24 different teams taking the fastest solve on at least one puzzle! A job well done to the following speedsters:
| Puzzle | Team | Solve time |
|---|---|---|
| Motion Capture | puzzles too hard :c | 11m25s |
| Broken Mirrors | ★ Starfall Stelle ★ | 13m31s |
| Sudoku Starter Pack | Qwilfish Disciples | 1h22m |
| Off by One | Typhlosion's Stupid, Beedrill Isn't | 11m16s |
| Musical Chairs | The Wob Blizzards | 43m1s |
| Tatami Mat | Typhlosion's Stupid, Beedrill Isn't | 7m15s |
| Cry-ptic | brain empty no thoughts | 13m45s |
| The Foggy Plains | Pusheen Appreciation Society | 5m11s |
| Plaintext Adventure | The C@r@line Syzygy | 42m46s |
| Jigsaudio | Eterna Citizens from /r/PictureGame | 34m54s |
| Dimmer Wits | ⛭ MISCELLANEOUS SYMBOL HISUIAN QWILFISH | 1h35m |
| LITS | Tiralmo | 2h34m |
| Trading Places | McGriddles fan club | 1h57m |
| Only Compact | Imperially Ornate Hisuian (redux) | 17m34s |
| No Word Wordsearch | pluru | 29m5s |
| The Haunted Graveyard | Hee-ho | 20m35s |
| Difference Maker v3.0 | The C@r@line Syzygy | 48m23s |
| Cross-Pollinator v2.4 | brain empty no thoughts | 1h9m |
| Fast-Fix Typist v2.7 | PERSON NAME OVERWATCH PLAYER COLORFUL DESCRIPTOR ENDEARING MONIKER DUBIOUS ACCOMPLISHMENT ONLINE HANDLE ANIME GIRL #1 FAN + friends | 12m51s |
| CV Writer v2018 | 🪀🦞🌮 | 1h25m |
| Answering Machine v9 | Projéctyl | 9m24s |
| The Abandoned Factory | [URGENT] EACH ANSWER IS A STRING OF LETTERS Z-A | 17m7s |
| Rig Your Own Tournament | weeklies.enigmatics.org | 4h15m |
| Ouroboros | Eevee’s Choices of /r/PictureGame | 1h47m |
| Homebrewed | Eevee’s Choices of /r/PictureGame | 42m46s |
| Cosmic Squad | ★ Starfall Stelle ★ | 1h13m |
| This Puzzle is Clearly Impossible | ★ Starfall Stelle ★ | 37m35s |
| Yesmystics | ⩀ MATHEMATICAL DIGLETT | 48m43s |
| The Frozen Tundra | bmtream | 21m8s |
| The Timespace Machine | Mathemagicians Traverse Caves Overconfidently, Ruins Obviously Need Extra Tampering | 14m46s |
Hints
Over the course of the hunt, we responded to 2,432 hints, including follow-up hints. We collectively wrote a total of 110,436 words' worth of hint responses, probably boosted significantly by some very detailed responses we gave on Dimmer Wits and Cross-Pollinator. Our median hint response time was 4 minutes and 40 seconds, with 94.9% of hints answered in under half an hour.
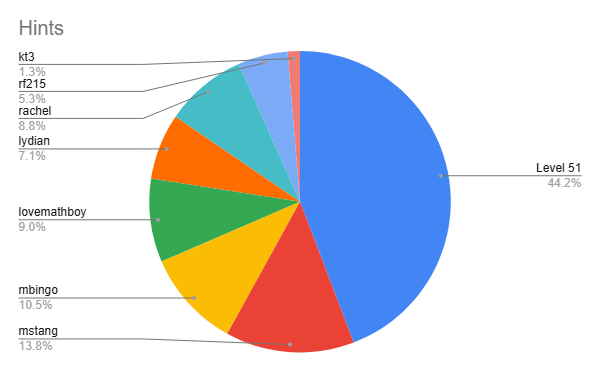
As always, we kept a leaderboard of which team members answered the most hints. Based on the chart below, you have a pretty good shot of guessing which team member wrote the responses to your hints:
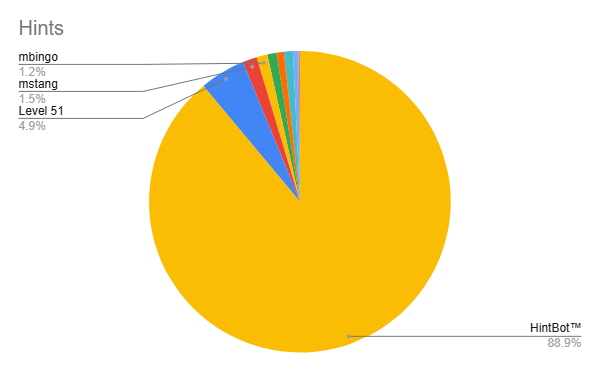
Of course, if we include a certain other hint answerer, the distribution is slightly more skewed.
Credits
Project lead: Level 51
Tech: Level 51, rf215
Puzzle editors: Level 51, mbingo
Puzzle authors: Jenna, Level 51, lovemathboy, lydian, mbingo, moo, mstang
Additional testsolvers: ALT, Deusovi, Dogfish44, kt3, Mistrals, Rachel, rf215, Walker
Art: lydian (hint/solve icons), Rachel (map art), uncredited anonymous artist (logo)